Crony Connect: Building investigative tools with R and Shiny
This post describes how I built Crony Connect, a tool to identify politically-connected individuals by cross-referencing public databases. I’m writing this because it might be helpful to others working on similar projects, and also as a reminder to myself of what the hell this code does, because no matter how many comments I add I will absolutely forget.
What is it?
The idea behind Crony Connect1 is simple: We want to identify politically-connected individuals. But there are two big challenges:
The databases we want to search are located in a bunch of different places, often in annoying formats (a PDF?? in the year 2021??!).
Individuals may exert influence indirectly - e.g. by donating via a firm, or giving an MP a cushy role at a think tank. So we need visibility on these “2nd-degree” connections.
So I wanted to create a tool that would provide access to multiple databases in one place, and would automatically identify companies associated with an individual and search for those too.
Under the hood
At present, Crony Connect draws on three public databases.
Companies House: an official database of company registrations that provides information on the sector of the company, its registered address, and the names of the directors.
Electoral Commission Donations: an official database produced by the Electoral Commission, which regulates political spending in the UK.
MP’s Register of Financial Interests: a database of the disclosures made by Members of Parliament about their financial interests, including outside employment, donations, gifts, hospitality, property, and shareholdings.
Querying the data
Companies House
Now I’ve identified 3 key databases, I need to figure out a way to let users query them with their own search terms. Companies House represents the best case scenario here: there’s a free API (woohoo!), and, even better, there’s an R wrapper for that API (woohoo\(^2\)!).
We want the user to be able to plug in a search term – in this case, the name of an individual – and get a list of companies associated with that individual in return. Thanks to the nifty CompaniesHouse R package, we can do this in just a few lines of code:
library(CompaniesHouse)
# "mkey" is my saved API key
# mkey <- "API_KEY_GOES_HERE"
# "input$ind_name" is the name that the user inputs
CompaniesHouse::DirectorSearch_limit(input$ind_name, mkey)This function returns a dataframe containing all the unique IDs in the Companies House database with a name matching the user input. As an example, let’s see what we get if we search for “Boris Johnson”:
CompaniesHouse::DirectorSearch_limit("Boris Johnson", mkey) %>%
# select variables to show
dplyr::select(person.name, year.of.birth) %>%
# return first 6 rows only
head()## person.name year.of.birth
## 1 Boris JOHNSON 1964
## 2 Dr David Boris JOHNSON-DAVIES 1955
## 3 Alexander Boris De Pfeffel JOHNSON 1964
## 4 BORISENCA TUDOREL INTREPRINDERE INDIVIDUALA NA
## 5 H & E JOHNSON NA
## 6 SIMON JOHNSON RIGHTS & BUSINESS LIMITED NAEven just looking at the first 6 results, we can immediately see that we’re getting some false positives. Only rows 1 and 3 could actually be THE Boris Johnson. Luckily, Companies House has to record the month and year of birth for all individuals on the register, so we can use that information to filter the results.
According to Wikipedia, BoJo was born in June 1964, so let’s add in that criterion:
results <- CompaniesHouse::DirectorSearch_limit("Boris Johnson", mkey) %>%
# select variables to show
# dplyr::select(director.id, person.name, month.of.birth, year.of.birth) %>%
# filter by month/year of birth
dplyr::filter(month.of.birth==6 & year.of.birth==1964)
print(results)## id.search.term director.id person.name
## 1 Boris Johnson QB7uR8yK-tBDW0HK9x1S3mbZ6aM Boris JOHNSON
## 2 Boris Johnson EZWa9WI6ur100VnMhfHT6EP4twA Alexander Boris De Pfeffel JOHNSON
## addess.snippet locality month.of.birth year.of.birth
## 1 The Queens Walk, London, SE1 2AA London 6 1964
## 2 13 Furlong Road, London, N7 8LS London 6 1964Nice! There are only 2 unique IDs in the Companies House database matching the name “Boris Johnson” with a date of birth in June 1964. We can probably assume that these refer to the same person, especially since both IDs are linked to addresses in London. (In fact, one of them seems to be… er, the London Eye?) Obviously, if we wanted to confirm this we’d need to do some manual verification. But the point of this tool is to provide leads for investigation, not to conclusively identify individuals. In other words: in this setting I’m more tolerant of false positives than false negatives.
This toy example has pointed us to an important feature of the Companies House database: the same individual might have multiple IDs. This is because Companies House does not verify or “clean” this data. So if BoJo lists himself as “Boris Johnson” on one form, and as “Alexander Boris De Pfeffel Johnson” on another, then the database has no way of knowing that these are the same person.
So the second piece of code we need is something to (i) store all the director ids that match the name and DOB inputted by the user; (ii) go through each director ID and return all companies associated with that ID.
# save all matching director IDs
director_ids <- results$director.id
# create an empty list to store values in
temp <- list()
# loop over the IDs
for (id in director_ids){
# find companies associated with each ID
temp[[id]] <- CompaniesHouse::indiv_ExtractDirectorsData(id, mkey)
}
# collapse the list back down into a dataframe
companies <- do.call("rbind", temp) %>% remove_rownames()
print(companies)## company.id comapny.name director.id
## 1 05490430 LONDON CLIMATE CHANGE AGENCY LIMITED QB7uR8yK-tBDW0HK9x1S3mbZ6aM
## 2 05774105 FINLAND STATION LIMITED EZWa9WI6ur100VnMhfHT6EP4twA
## directors director.forename director.surname
## 1 Boris JOHNSON Boris JOHNSON
## 2 Alexander Boris De Pfeffel JOHNSON Alexander JOHNSON
## start.date end.date occupation role residence postcode
## 1 2008-05-05 2010-08-23 Mayor Of London director NA SE1 2AA
## 2 2006-04-07 2008-05-23 Editor/Politician director NA N7 8LS
## nationality birth.year birth.month appointment.kind download.date
## 1 British 1964 6 personal-appointment 20/06/2021 01:46:41
## 2 British 1964 6 personal-appointment 20/06/2021 01:46:41Now we’re cooking! We have identified two IDs, which are each linked to one company. The first is a municipal company connected to Johnson’s former role a Mayor of London. The second, “Finland Station Limited”, is a now-dissolved TV production company that paid Johnson £30,000 to present a TV documentary about the fall of Rome.

I saw this and now so must you
OK! Now we want to take those company names and feed them (along with the name of the associated individual) into some other databases.
BUT: we should probably do some data processing first. Since Companies House is the registrar of limited companies, most (all?) of the company names have “Limited” or “Ltd” at the end. We want to exclude these types of filler words to avoid clogging up our search, so “Finland Station Limited” becomes “Finland Station”. Here’s a non-exhaustive list of corporate-name-fillers that I came up with by browsing some company names:
temp <- gsub("Limited", "", results2()$comapny.name, ignore.case=T)
temp <- gsub("\\s*\\([^\\)]+\\)","", temp, ignore.case=T)
temp <- gsub("llp","", temp, ignore.case=T)
temp <- gsub("partners","", temp, ignore.case=T)
temp <- gsub("associates","", temp, ignore.case=T)
temp <- gsub("holdings","", temp, ignore.case=T)
temp <- gsub("group","", temp, ignore.case=T)
temp <- gsub("foundation","", temp, ignore.case=T)
temp <- gsub("the","", temp, ignore.case=T)
temp <- gsub("of","", temp, ignore.case=T)
temp <- gsub("and","", temp, ignore.case=T)
temp <- gsub("&","", temp, ignore.case=T)
temp <- gsub("ltd","", temp, ignore.case=T)Electoral Commission donations database
Over to our second database! The Electoral Commission donations database. Sadly they don’t have an API, but the dataset isn’t huge and it’s simple enough to download the whole thing at once. At the bottom of the search results there’s an option to “Export as .csv”. If we leave the search field blank then it will return the whole dataset. Then we just need to do some HTML sleuthing: right-click on the “Export” button and go to “Inspect” (in Chrome). From here we can find the download link.
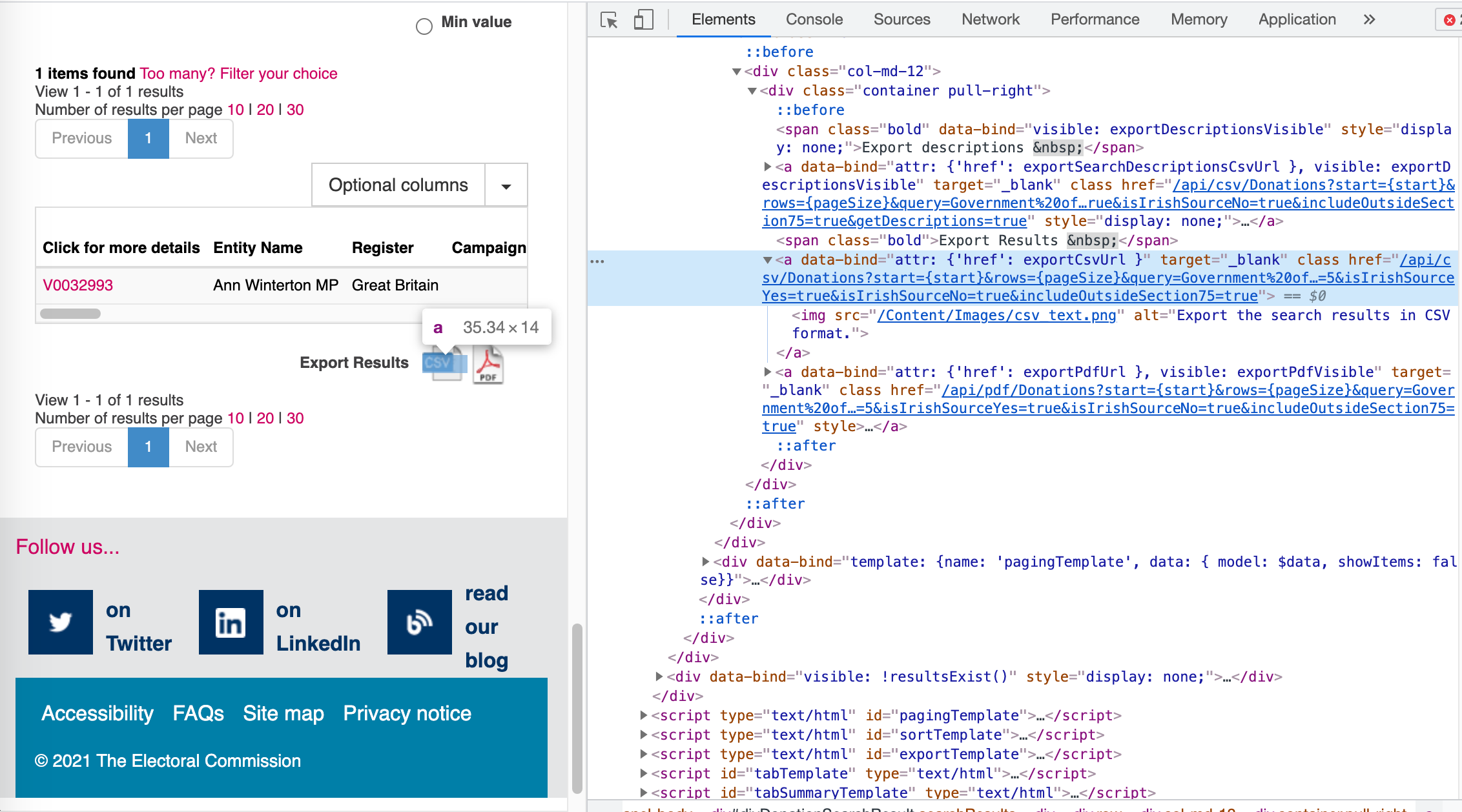
Screenshot of the Electoral Commission search page
In fact, the link tells us that there is an API, but as I said the dataset isn’t huge so I’m feeling like the path of least resistance is to just write a script to automatically re-download the whole dataset everyday to refresh the data and then perform the search within the Shiny app. (Note: this is not how you are supposed to use an API!)
# collect all search terms
# individual name + list of associated companies
search_terms <- c(input$ind_name, company_names())
# paste together in the format:
# term1|term2|term3|...
# this is regex for "term1 OR term2 OR term3 OR ..."
search_terms_regex <- paste(search_terms, collapse="|")
# use stringr to find rows of the dataset in which the Donor Name field contains any of the search terms
temp <- donations[stringr::str_detect(toupper(donations$DonorName), toupper(search_terms_regex)),] %>%
# then select the columns to display
select(RegulatedEntityName, DonorName,
Value, DonationType, AcceptedDate, ReportedDate)This is pretty straightforward, the main hurdle was overcoming my obstinate refusal to ever learn what regex actually is, and just googling what I need case-by-case.
I’d also like to highlight the search term in the results table, so it’s obvious to the user why that result came back. To do that, I used a fairly clunky double loop (though I’m not too worried about efficiency here because the loop only operates on the rows with matches, not the full dataset).
Below, matches is a list where each element is a character vector of the matched search terms in that row of the dataset. So the i index loops over rows, and the j index loops over matched search terms in that row. In this instance, we’re searching the DonorName field so we’re unlikely to have two or more search terms matching the same cell. However, I want to account for that possibility in the code because we’ll need it for the next database!
# out of all the rows that matched one of the search terms,
# extract all the matched search terms row-by-row
matches <- stringr::str_extract_all(tolower(temp$DonorName), tolower(search_terms_regex))
# loop over rows (i) and then matched search terms (j):
for (i in 1:length(matches)){
for (j in 1:length(matches[[i]])){
# use str_replace to add HTML highlilght tags
# on either side of the matched search term
temp$DonorName[i] <- stringr::str_replace_all(
toupper(temp$DonorName[i]),
toupper(matches[[i]][j]),
paste0("<mark>", toupper(matches[[i]][j]), "</mark>")
)
}
}Here’s a screenshot of what the output will look like once it’s rendered as a DataTable in Shiny:
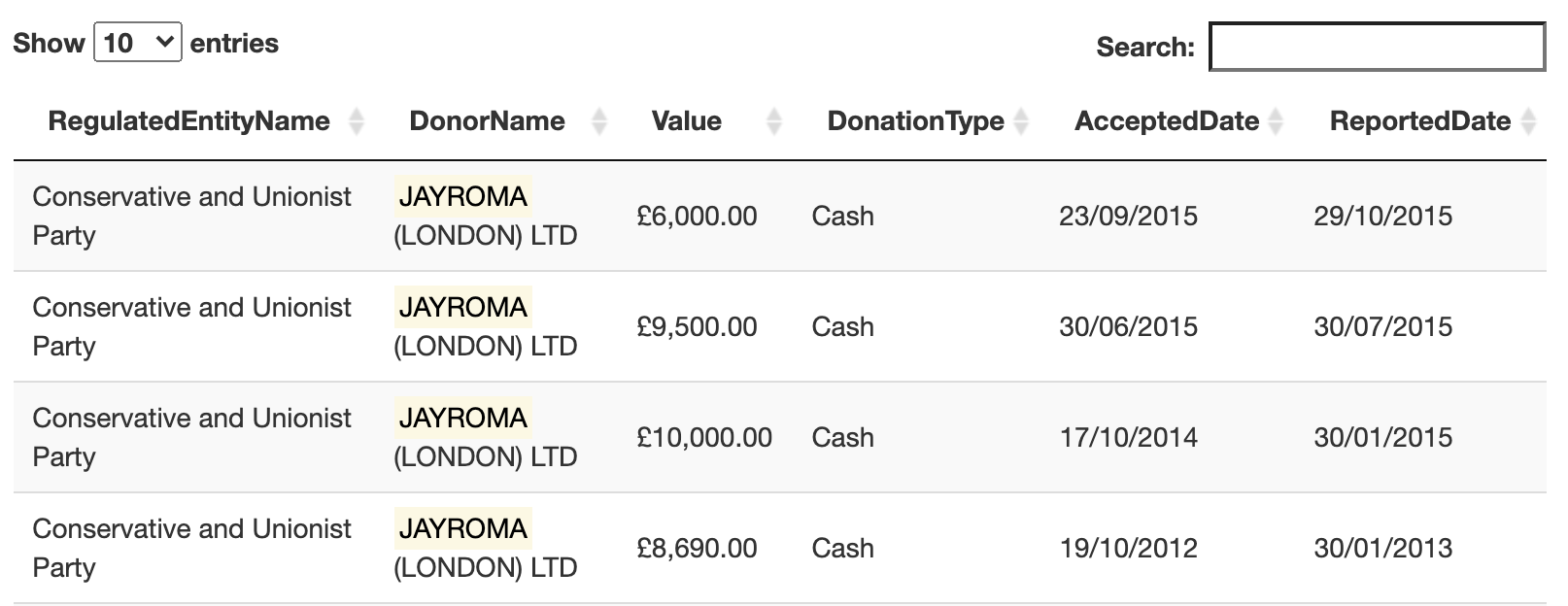
Screenshot of donations search results
DataTables are pretty cool because they are themselves interactive: users can filter, sort, and search within the table widget themselves. Fun!
MP’s register of financial interests
Onward and upwards… now let’s move on to the MP’s register of financial interests. This is certainly the biggest challenge yet. Mainly because parliament has decided to format this data as either a PDF or a vaguely unstructured chunk of HTML. Fortunately, some good data samaritans have compiled this into an easily searchable database! Nice. They also set up a free API (NICE) but unfortunately I haven’t been able to figure out how to return exact matches, and so I’m getting way too many irrelevant results.
So I’ll continue with my blatant disregard for APIs by simply scraping the whole dataset and performing the search within the Shiny app. (Again: this is not what you are supposed to do.) I did try to scrape it “politely”, by waiting a few minutes before downloading each new .csv file. I have set up another automated script to download any new registers as they become available.
The main bit of data cleaning here was to notice that this dataset has a LOT of duplicate entries. I ended up with a dataset of about 290,000 rows, and this index only goes back to 2017?? That’s like 90 financial interests per MP per year! Fortunately, I realized many of the entries are duplicated because the register is re-published as a new file each time it is updated. Once we remove those dupes we’re left with a much more manageable dataset of about 17,000 rows (about 5 financial interests per MP per year - much more reasonable!).
And here’s some even better news: we already have the necessary code to feed in the search terms and highlight any matching results from the section above! Here’s what it will look like once rendered as a DataTable in the Shiny app:
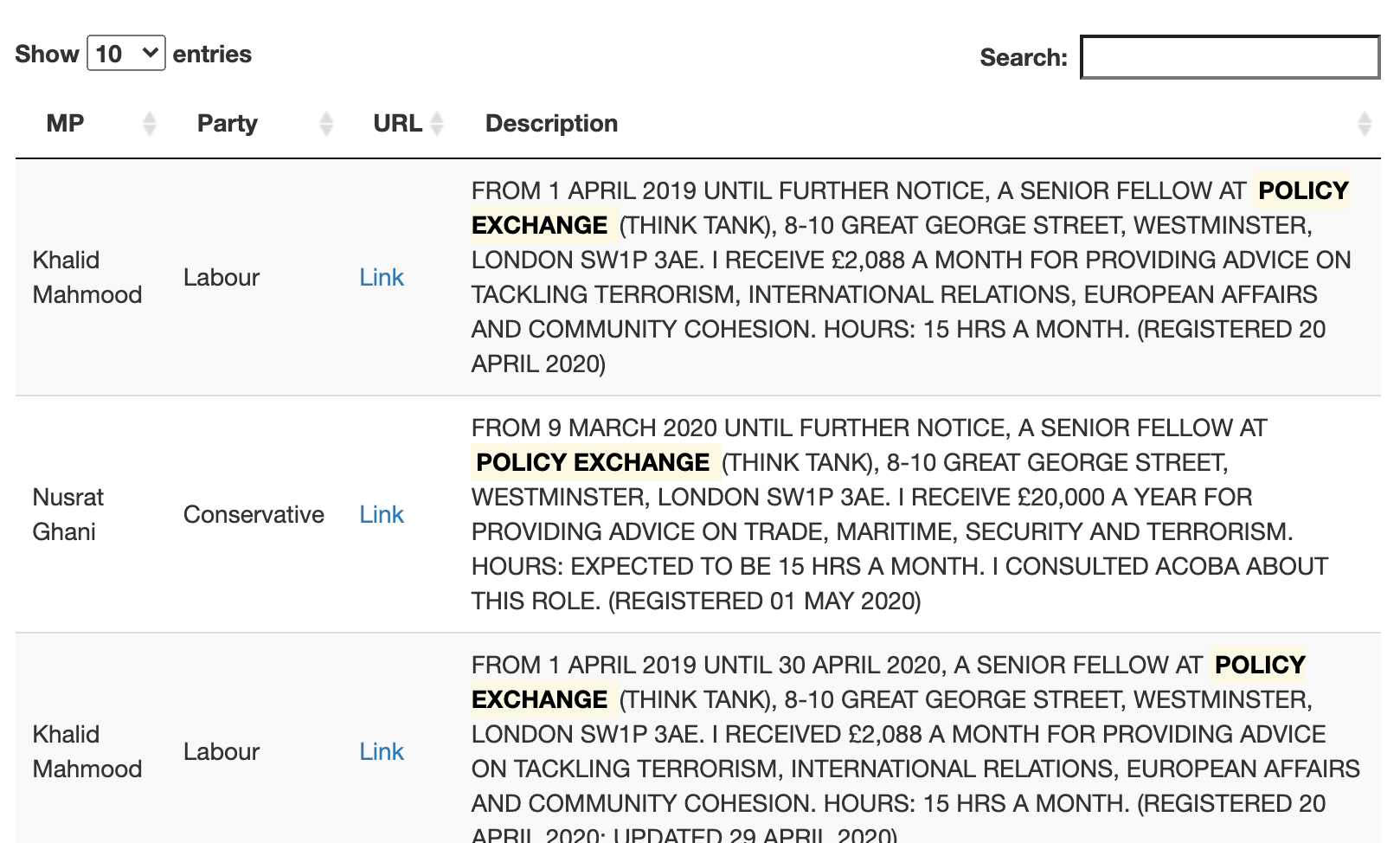
Screenshot of MP register search results
As you can see, the register of financial interests contains a lot more text than the donations database. This means that the search function here is going to take quite a bit longer, even though the financial interests dataset is smaller in terms of rows. I switched from base R (grepl) to the stringr package for pattern matching, though there are probably more performance improvements to make here.
In the meantime, in order to make this delay less annoying to the user, I’ve put the register of interests as the final tab in the app. That way, the user can see the lightening-fast results from Companies House and the somewhat-speedy results from the donations database before they reach the final tab. The other tweak I made was to add a loading animation, so the user knows that something is happening under the hood and the app isn’t just frozen. The shinycssloaders package makes this super easy to integrate into a Shiny app.
Designing the Shiny app
Phew! Now everything is working under the hood, we need to design a beautiful and intuitive user interface so that people will actually want to use this app!
One of the nice things about Shiny is that is has a bunch of built-in formats, like a sidebar panel that takes up (I think) 1/3 of the horizontal space, and tabsets that allow you to display a lot of information on one page. I used both of these features to design the layout of Crony Connect:
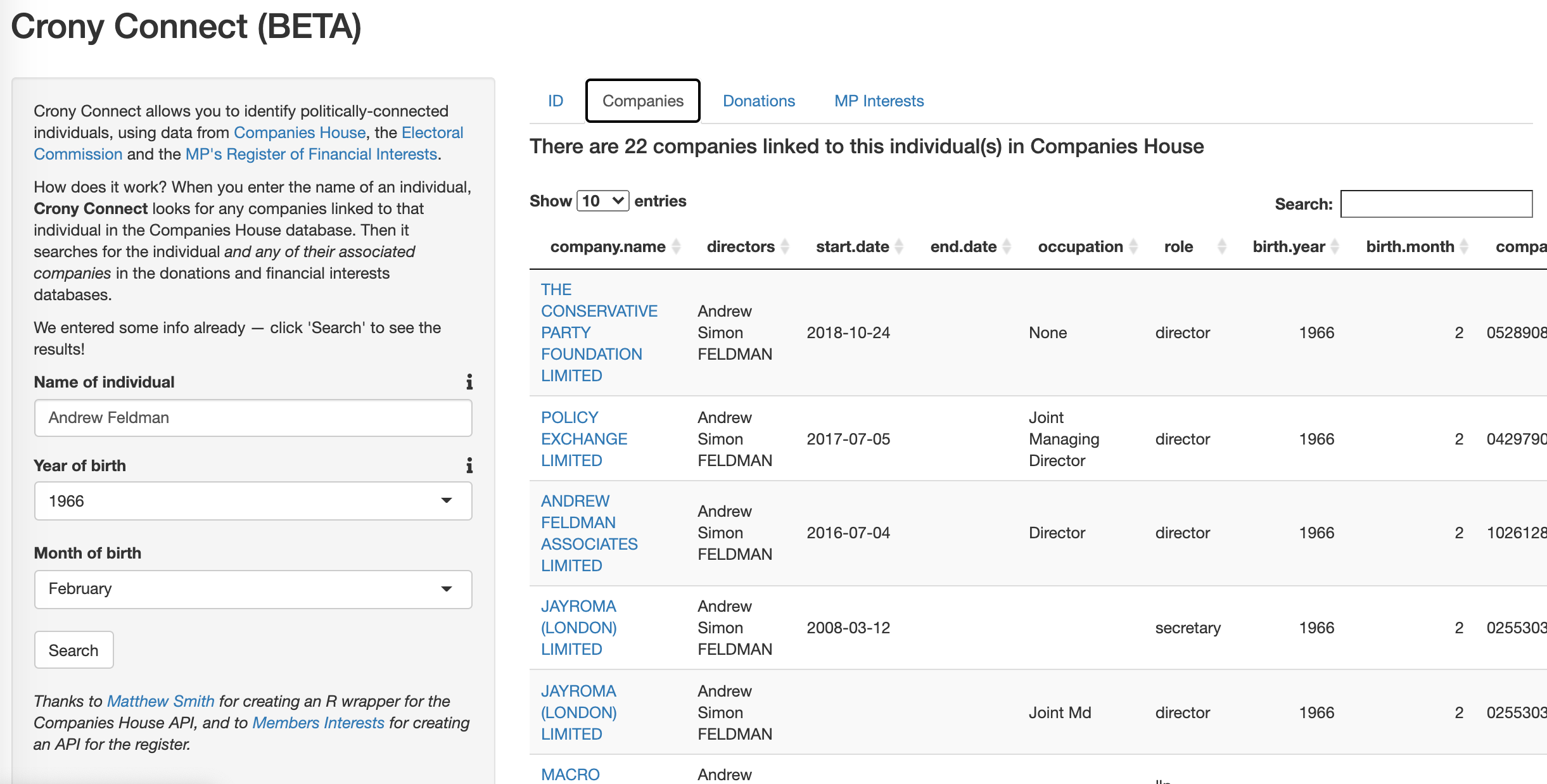
Screenshot of Crony Connect
Remarkably, it actually looks kind of OK on mobile, too? But I’m not too worried about that since I imagine that most people who actually want to use this (as opposed to just looking!) will be on a tablet or laptop-sized screen.
Having said that, it is a bit overwhelming to look at, so we obviously need to guide the user around a bit. The sidebar gives a basic description of what the app does and which databases it relies on. However, people enjoy clicking buttons much more than they enjoy reading words, so I’ve also pre-populated the search fields with the name of a very well-connected individual who crops up in all 3 databases. This functions as a sort of built-in “tutorial” for how the app works and what the results will look like.
Using the bsplus package we can add some Bootstrap elements to our Shiny app to create mini “informational” pop-ups. In this case: to remind the user that individuals may be listed under different variations of their name, and to explain that the year/month of birth fields can be set to “unknown” to return all matches.
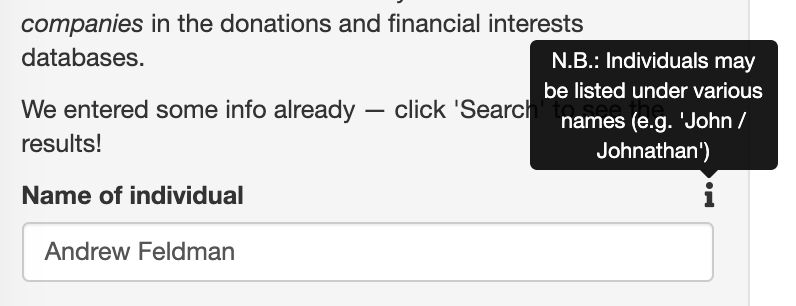
Screenshot of pop-up on search field
To do
Working prototype!
Add more datasets (Lords’ financial interests? APPG registers?)
Improve search speed
Add some legal disclaimers so I don’t get sued for (implicitly) calling someone a crony?
As always, please feel free to email me (sophie DOT eva DOT hill AT gmail.com) or say hi on Twitter if you have feedback on this project! If you didn’t get enough of the gory details in this post, the full code is on Github.
For the uninitiated, this is my feeble attempt at a pun on the nerdy British gameshow, Only Connect.↩︎